In unserem zweiten Artikel dieser Serie werden wir erneut ein Backend zum Speichern und Abfragen von Daten erstellen. Als Cloud-Anbieter werden jetzt die Amazon Web Services (AWS) verwendet.
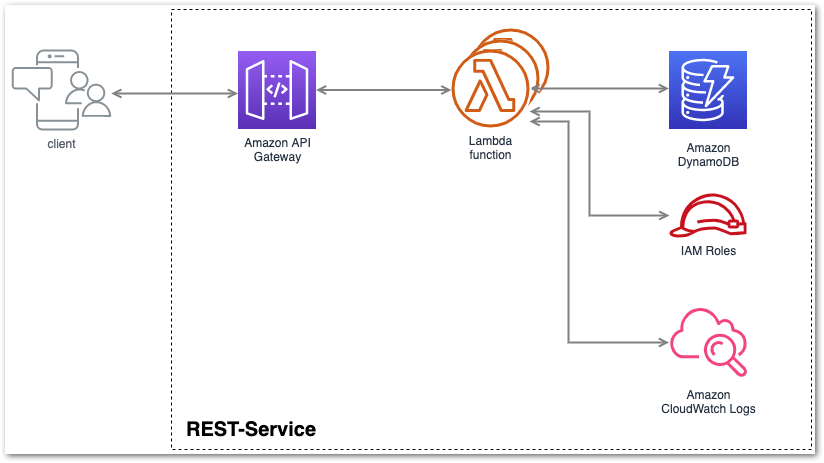
Im Gegensatz zu der Azure-Implementierung unseres Backends werden wir bei AWS den REST-Service nicht selber implementieren. Stattdessen werden wir bestimmte AWS-Services verwenden, welche uns eine Servless-Implementierung des kompletten Backends ermöglicht. Bei Servless müssen wir uns keine Gedanken um etwaige Dienste machen, die wir Verwalten und mit Code deploymen müssen. All dieser administrative Overhead wird uns von AWS abgenommen.
Für unseren servless REST-Backend werden für von AWS folgende Services verwenden:
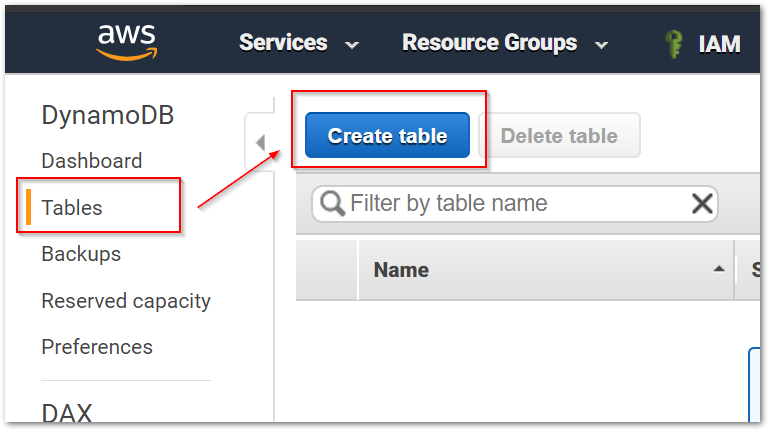
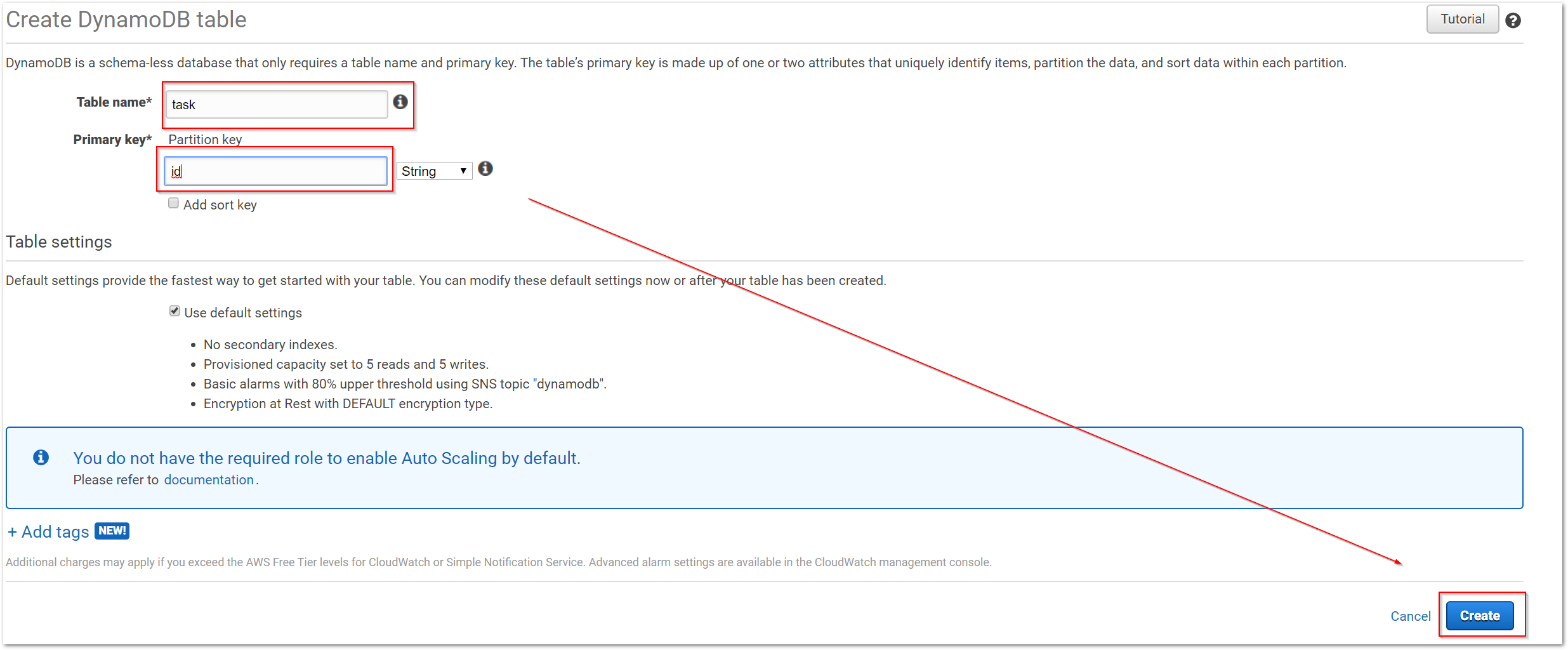
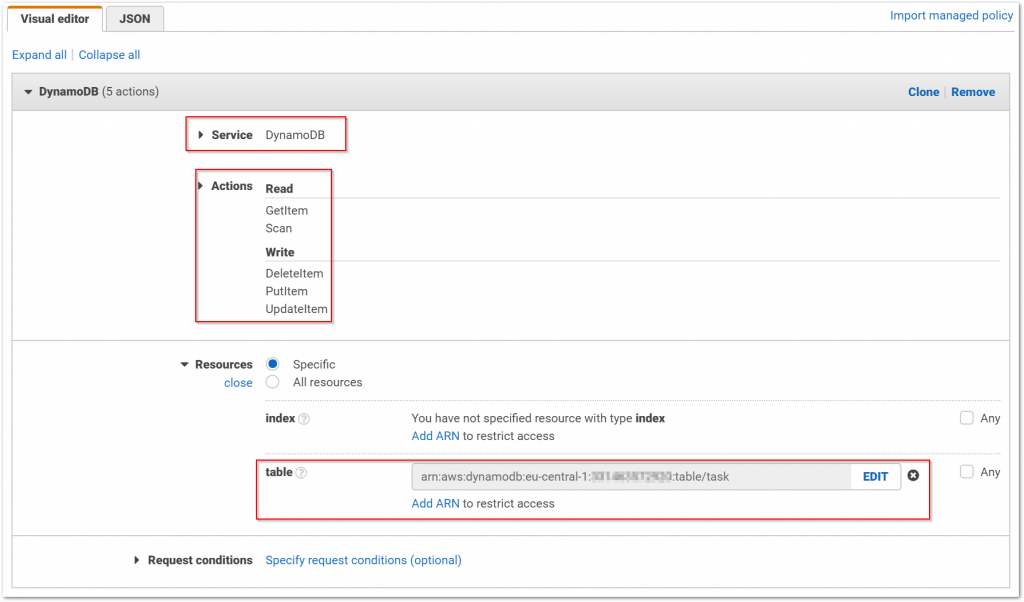
Die DynamoDB ist eine klassische NoSQL-Datenbank, wobei sich Amazon bei der Benennung der Sache in der AWS-Konsole eher an die klassischen Begriffe einer relationalen Datenbank orientiert hat. Daher legen wir eine neue Tabelle an und vergeben einen Primärschlüssel.
Ein Entscheidender Unterschied zu der Azure Cosmos-DB besteht darin, dass wir keine DynamoDB-Instanz erstellen müssen. AWS stellt den Service bereit und ermöglicht den Entwickler nur die Anlage von Tabellen und Daten. Um sicherzustellen, dass nicht jede Anwendung alle Tabellen des von AWS bereitgestellten DynamoDB-Service verwenden kann, müssen wir IAM-Rollen anlegen, welche den Zugriff auf die Tabellen und die erlaubten Operationen steuert.
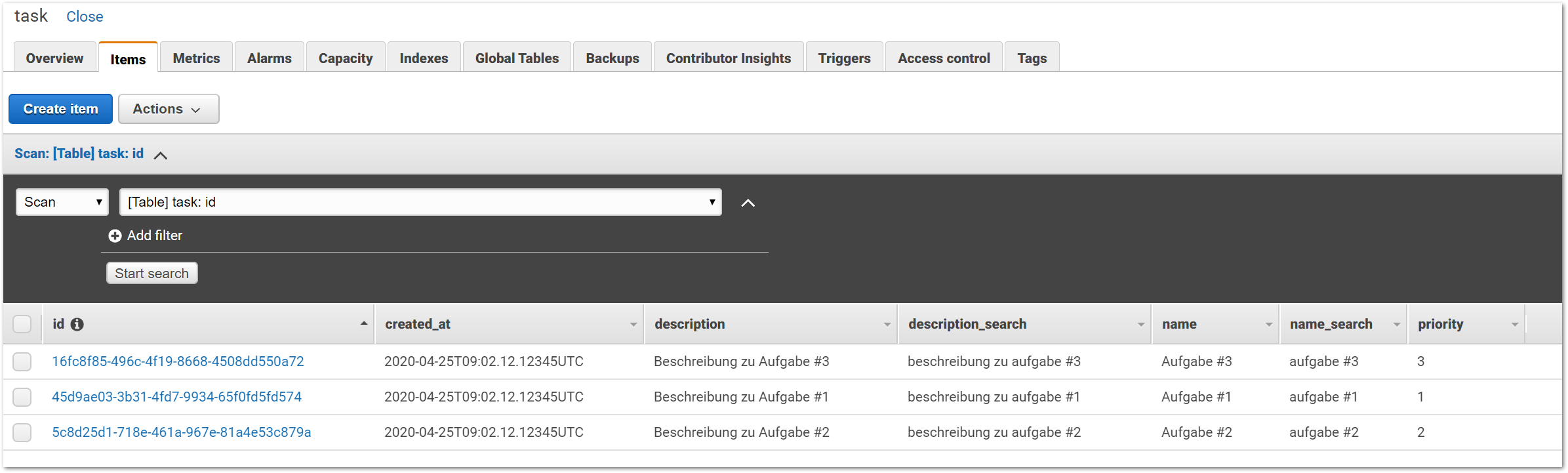
Als nächstes legen wir eine Lambda-Funktion an. Sie hat die einfache Aufgabe, die Daten von einem HTTP-Request in Daten für eine DynamoDB zu transformieren. In diesem Beispiel ist dies anhand der Anlage eines Tasks dargestellt.
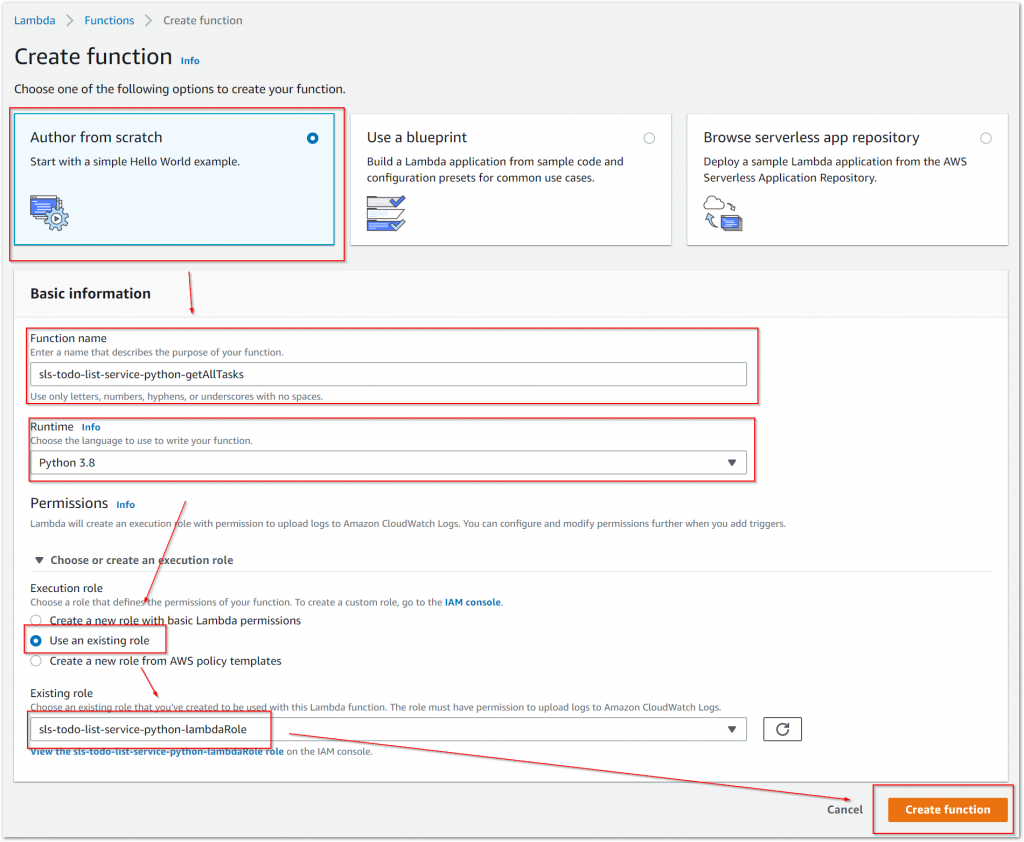
Zu allererst müssen wir die Lambda-Funktion anlegen. Dazu vergeben wir einen Namen und wählen eine Runtime aus. Neben den Verfügbaren Runtimes wie Node.JS, .NET und Java wählen wir hier aber Python. Als nächstes ist es wichtig, dass wir unsere eben angelegt Ausführungsrolle hinterlegen, da nur so die Lambda-Funktion die Berechtigung auf das Arbeiten der angelegten Tabelle in der DynamoDB erhält.
taskimport boto3
import json
import shared
import uuid
from datetime import datetime, timezone
from decimal import Decimal
from botocore.exceptions import ClientError
def lambda_handler(event, context):
taskTable = boto3.resource('dynamodb').Table("task")
body = json.loads(event['body'])
newTask = {
'id': str(uuid.uuid4()),
'name': body['name'],
'name_search': body['name'].lower(),
'priority': Decimal(body['priority']),
'description': body['description'],
'description_search': body['description'].lower(),
'created_at': datetime.now(timezone.utc).strftime('%Y-%m-%dT%H:%M:%S.%f%Z')
}
try:
response = taskTable.put_item(Item = newTask)
except ClientError as err:
print(err.response['Error']['Message'])
return shared.respond(err)
else:
return shared.respond(None, newTask)
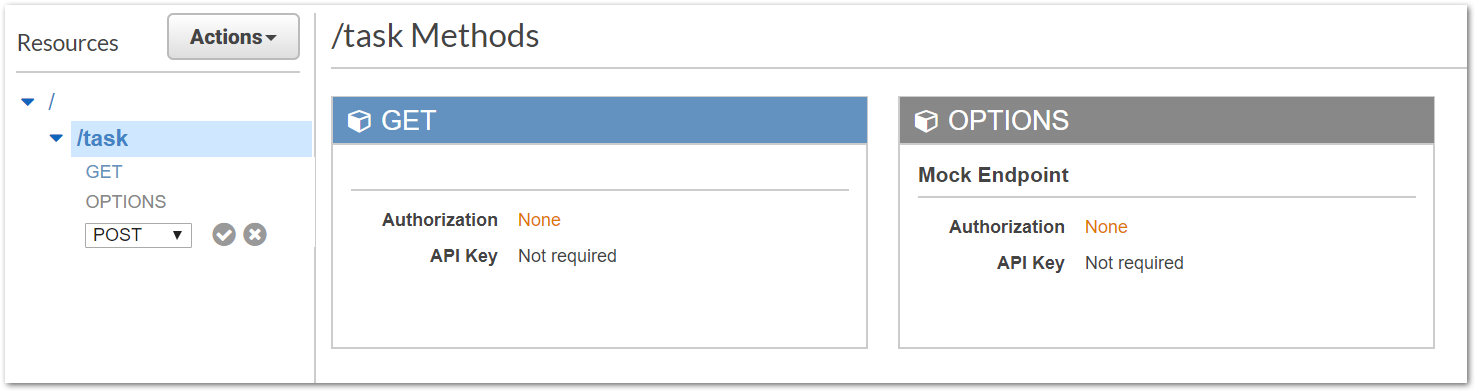
Alle bisher angelegten AWS-Services sind nur intern aufrufbar. Damit unsere Anwendung darauf zugriff hat, müssen wir ein API-Gateway anlegen. Dieser ist ein konfigurierbarer REST-Service, indem wir die Pfade und Methoden beliebig konfigurieren können.
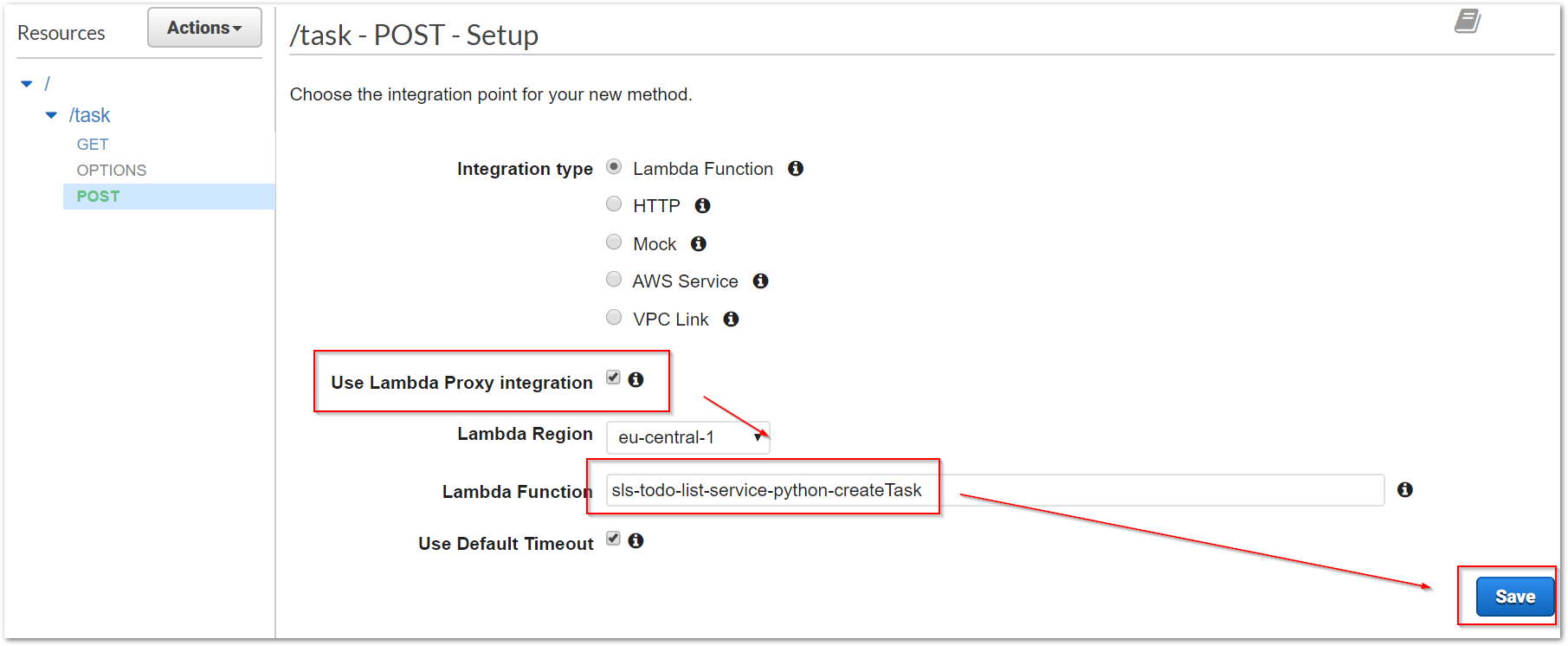
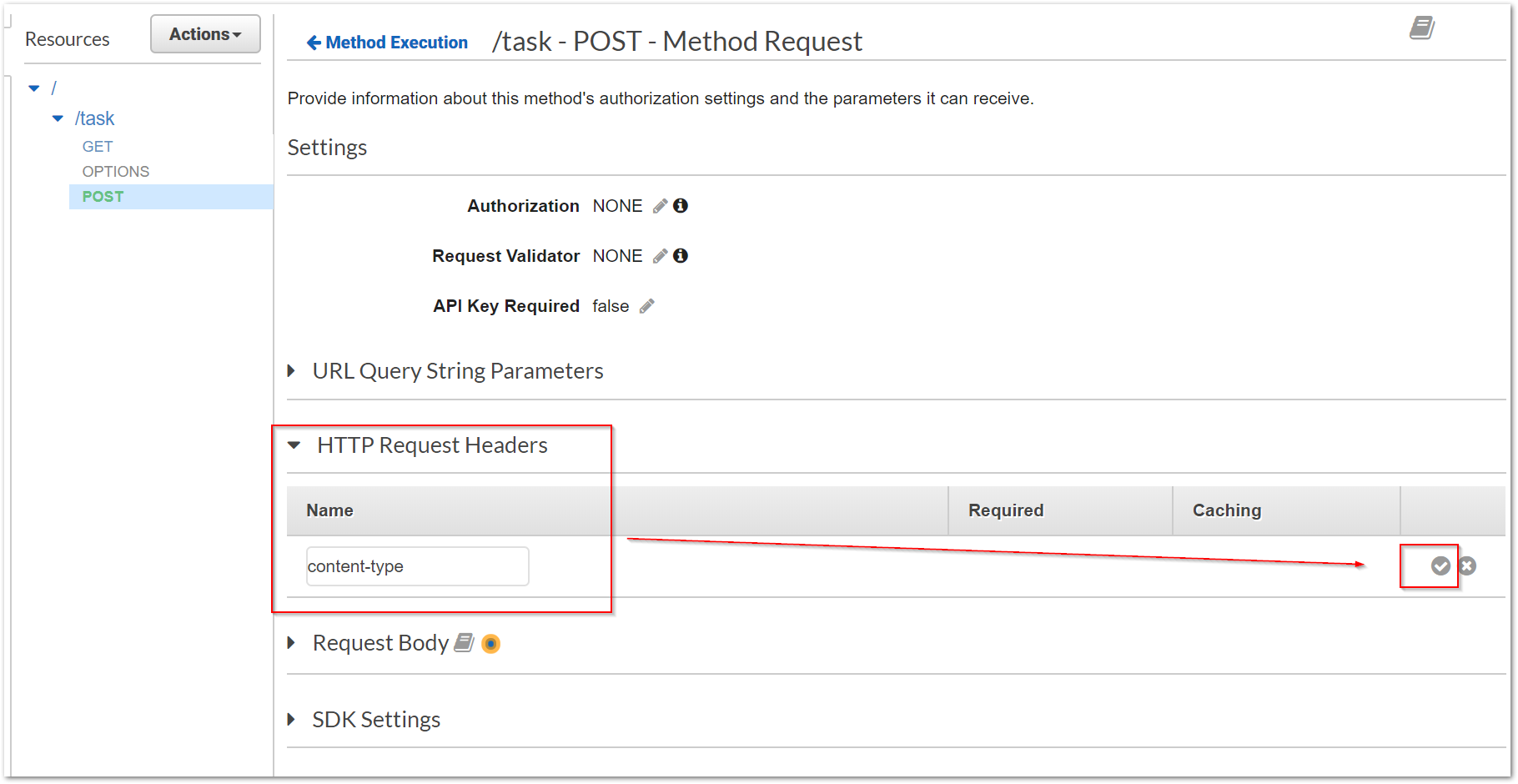
Um bei dem Beispiel der Anlage eines neuer Aufgabe zu bleiben, beschreibt die folgende Bilderreihe die Schritte zur Anlage einer POST-Methode, welche für die Anlage aufgerufen werden soll. Dazu stellen wir bei der Anlage ein, dass der entgegengenommene Request an unser Lambda weitergereicht werden soll.
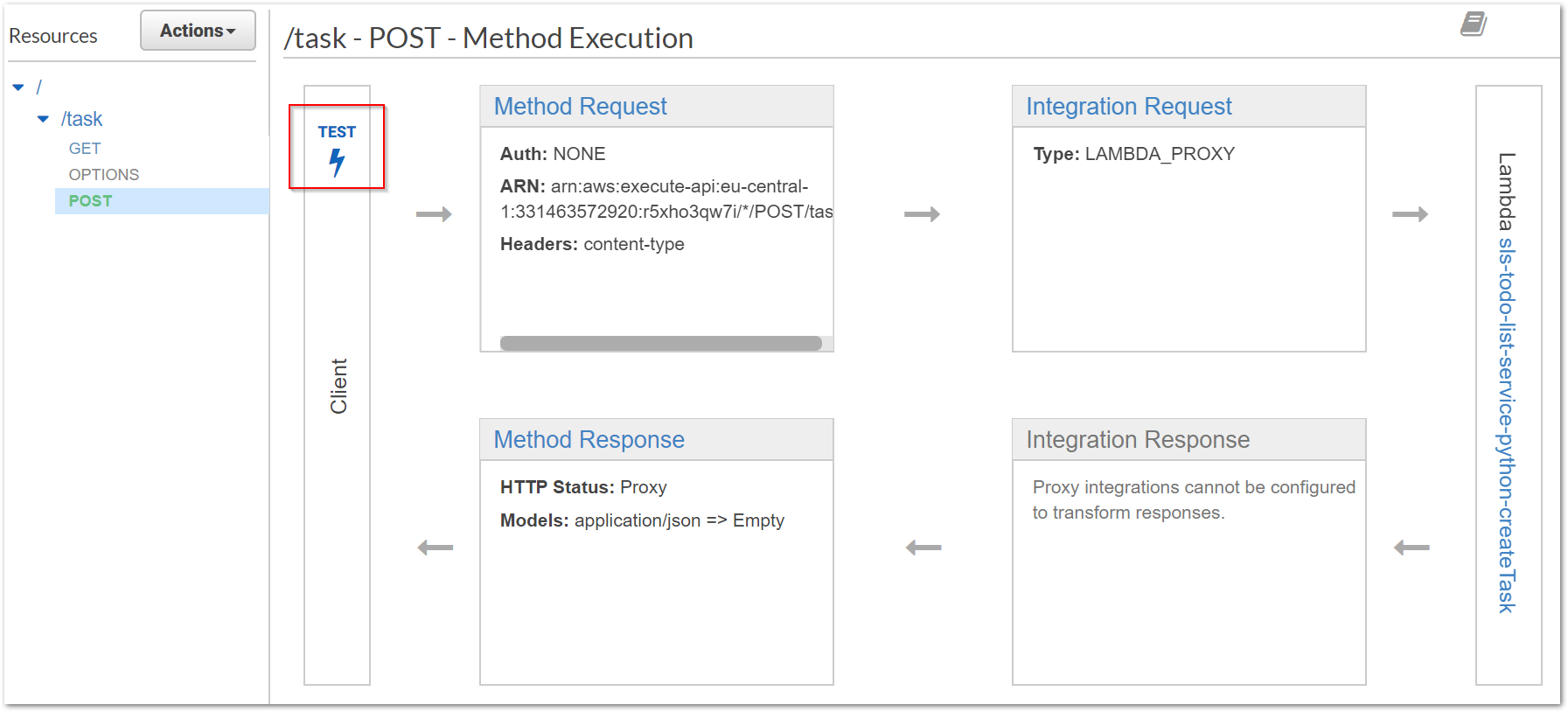
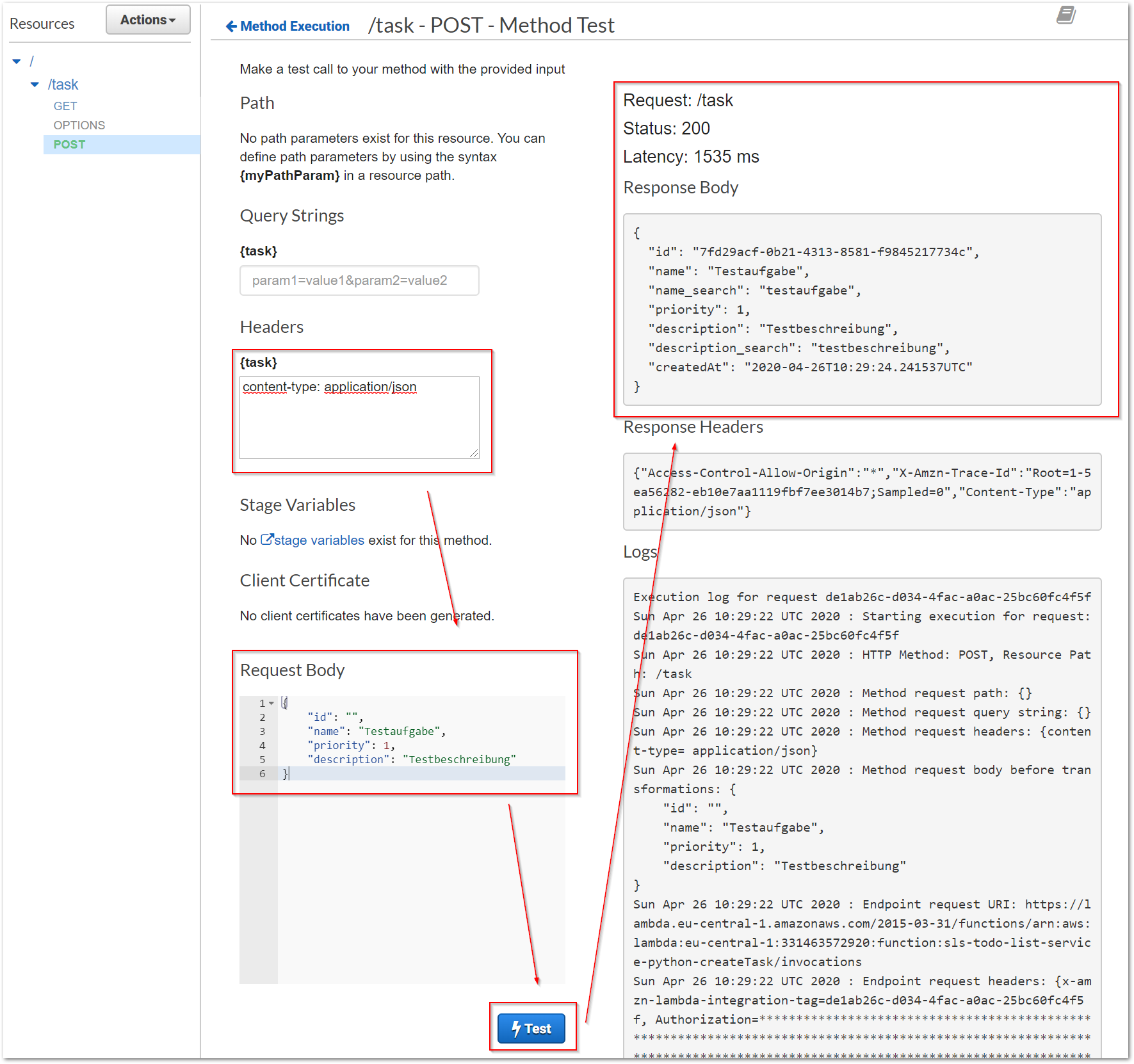
Das API-Gateway bietet uns zusätzlich die Möglichkeit, die Methode direkt testen zu können. So können Konfigurationsfehler schnell erkannt und behoben werden.
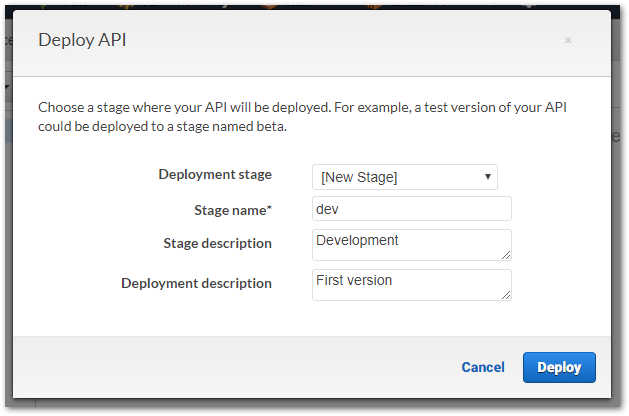
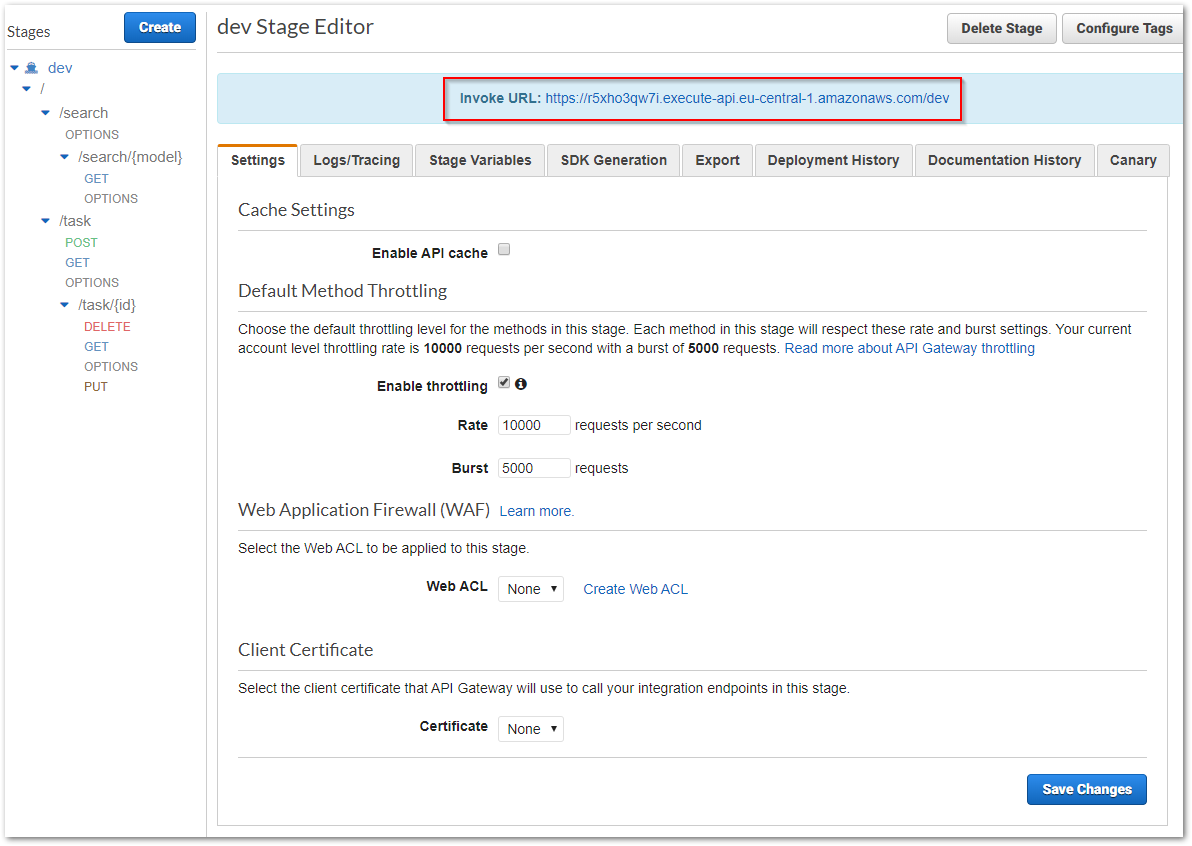
Mit der Anlage der API im API-Gateway ist es aber noch nicht getan. AWS ermöglicht die Bearbeitung der API ohne dass davon eine ggf. laufende Anwendung beeinträchtigt wird. Dies wird erreicht, in dem eine API vor der externen Nutzung veröffentlicht werden muss. Eine API kann auch mehrfach veröffentlicht werden, was somit auch eine Versionierung der API ermöglicht.
swagger.json).