Container as a Service (CaaS) ist ein cloudbasierter Service mit dem Container deployed, ausgeführt, skaliert und verwaltet werden können.
Im AWS Umfeld finden wir zwei solche Services, nämlich den Elastic Container Service (ECS) und den Elastic Kubernetes Service (EKS). In diesem Artikel, werden wir die zwei Services vorstellen und ihre Eigenschaften und Einsatzzwecke auflisten.
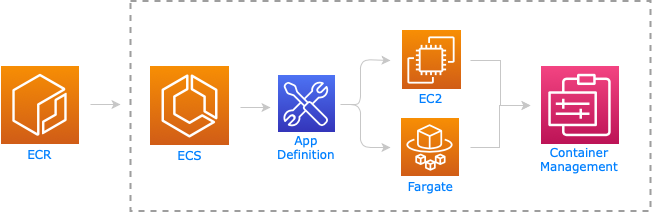
Ein ECS Cluster beinhaltet alle Services, die das Verwalten (Scheduling, Load Balancing, Container Lifecycle) der Container ermöglichen.
Die Container werden auf EC2 Instanzen gehostet, die zum Cluster verbunden sind. Auf jeder Instanz muss die Container Runtime (z.B. Docker) und ein ECS Agent installiert werden, der die Kommunikation zwischen der Control Plane (ECS) und der entsprechenden EC2 Instanz ermöglicht.
Obwohl wir die Verwaltung der Container dem ECS Service überlassen haben, müssen wir uns um die virtuellen Maschinen (EC2 Instanzen) selbst kümmern. Darunter versteht man z.B. :
EC2 lässt sich schnell und einfach mit anderen AWS Services integrieren :
Wenn wir ein EKS Cluster erstellen, werden automatisch die Kubernetes Master Nodes deployed und der Kubernetes Master Service darauf installiert. Diese Master Nodes sowie die Etcd Datei, die den Zustand und Konfiguration des Clusters beschreiben, werden auf alle Availability Zones der ausgewählten AWS Region repliziert.
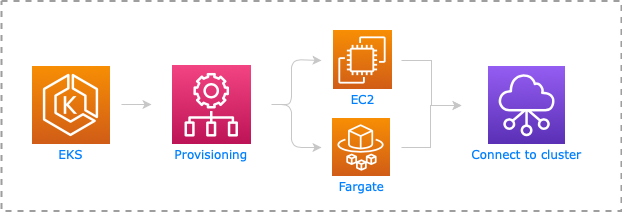
Für die Worker Nodes können wir, wie bei ECS, EC2 Instanzen benutzen, die wir zu unserem EKS Cluster verbinden. Die Kommunikation zwischen Control Plane (Master Nodes) und den VMs erfolgt über Kubernetes Worker Processes (Analog zum ECS Agent für ECS)
Wenn wir uns mehr auf die Entwicklung der Anwendung und weniger auf die Infrastruktur fokussieren wollen, können wir entweder Fargate für eine fully-managed Compute-Fleet oder EC2 Instanzen benutzen. Es gibt allerdings eine dritte semi-managed Option – Nodegroups.
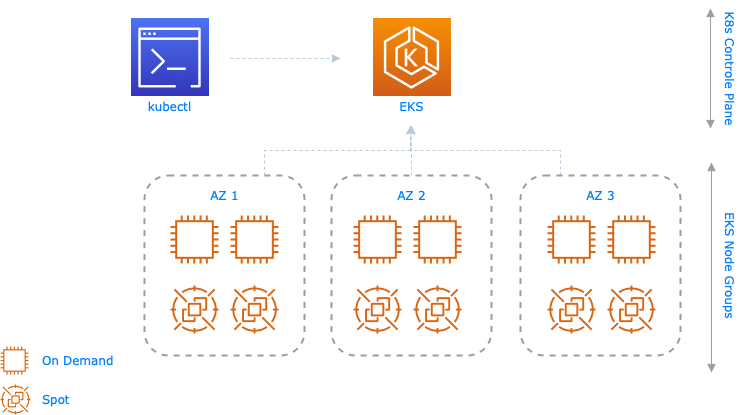
Eine Nodegroup (Autoscaling group + zugehörige EC2 Instanzen) übernimmt das Provisioning und die Verwaltung der Lifecycles von Nodes (EC2 Instanzen) für EKS Clusters. Jede Nodegroup benutzt die Amazon EKS-optimized Amazon Linux 2 AMI. Außerdem werden alle Nodes einer Nodegroup automatisch markiert (tagged) für die auto-discovery vom Kubernetes Cluster auto-scaler.
AWS Fargate ist ein serverloser Compute Engine Dienst für Container, der uns die oben genannten Verantwortungen übernimmt.
Wenn wir ein Container an Fargate übergeben, wird der Service Analysen durchführen, um zu schätzen, wie viel Ressourcen (CPU, RAM, …) dieser Container benötigt. Anhand dieser Informationen wird dann automatisch ein Server instanziiert, worauf der Container letztlich laufen wird. Damit müssen wir uns nicht mehr um die EC2 Instanzen kümmern und werden nur für die Ressourcen bezahlen, die unsere Container auch benötigt.
Der Nachteil eines solchen Einsatzes ist es, dass wir unflexibel sind, wenn wir mehr Konfiguration und Kontrolle über die VMs brauchen. In diesem Fall sind EC2 Instanzen eher zu empfehlen.
Spot Instanzen sind nicht genutzte EC2 Instanzen, die den AWS Kunden als Kaufoption mit erheblichen Ermäßigungen (bis zu 90%) zur Verfügung gestellt werden.
Es gibt zwei Strategien bzw. Möglichkeiten, wie Spot Instanzen bei einer Spot-Anfrage zur Verfügung gestellt werden können.
Nimmt Instanzen aus dem Spot Instance Pool, die den niedrigsten Preis verlangen. Wenn der Preis sich ändert, wird die Instanz terminiert und durch eine billigere (falls vorhanden) ersetzt.
Nimmt Instanzen aus dem Spot Instance Pool mit optimaler Kapazität, ohne Rücksicht auf den Preis. Im Gegensatz zu der lowest-price Strategie, wird die Änderung des Preises für eine Instanz nicht zu einer Terminierung führen.
In einer verteilten Architektur (z.B. Microservices) ist es extrem wichtig den Status aller aktiven Komponenten zu überwachen. Hierfür brauchen wir einen komplexeren Monitoring Service als bei einer monolithischen Anwendung, da eine einzige Anomalie einen entscheidenden Prozess beeinträchtigen könnte. In diesem Abschnitt stellen wir AWS Services vor die uns ermöglichen Anomalien auf Komponentenebene zu identifizieren, Metriken von verschiedenen Quellen der Anwendung zu sammeln und daraus Visualisierungen zu erstellen.
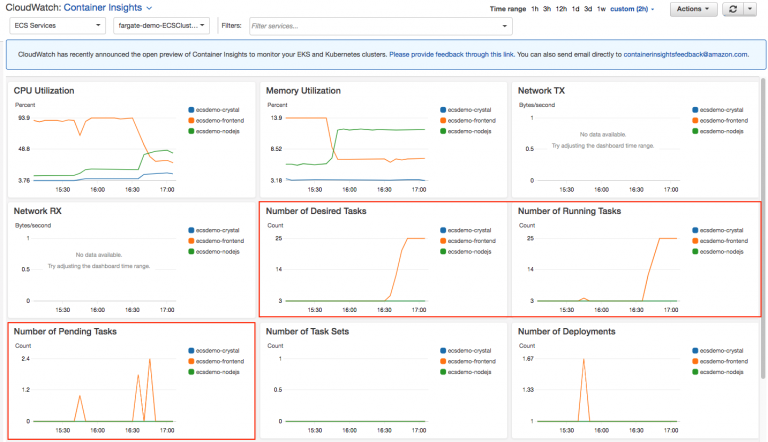
Container Insights stellt uns Diagnoseinformationen und Metriken bereit (CPU, Memory, Network, Container Restart Failures, etc….). Aus diesen Metriken werden automatische Dashboards generiert, die uns helfen auftretende Probleme zu identifizieren und isoliert zu behandeln. Dieser Service ermöglicht uns auch, Alarme zu definieren, falls bestimmte Metriken definierte Thresholds unter- oder überschreiten. Außerdem können wir eigene Metriken sammeln und persönliche Dashboards einrichten, um diese Metriken zu visualisieren.
Amazon X-Ray ist ein Service zum Analysieren und Debuggen verteilter Anwendungen, die z.B. über eine Microservice Architektur verfügen.
Der Service verfolgt ankommende Requests auf dem Weg durch einzelne Komponenten der Anwendung. An jeder Stelle werden Daten und Ressourcen zusammengefasst, aus denen am Ende eine End-to-End Ansicht der kompletten Anwendung abgebildet werden kann. Dies ermöglicht uns Anomalien schneller und präziser zu identifizieren, dadurch dass wir feststellen können, an welchen Stellen diese Anomalien stattfinden.
Das folgende Diagramm soll den Prozess und seine einzelne Schritte von X-Ray veranschaulichen
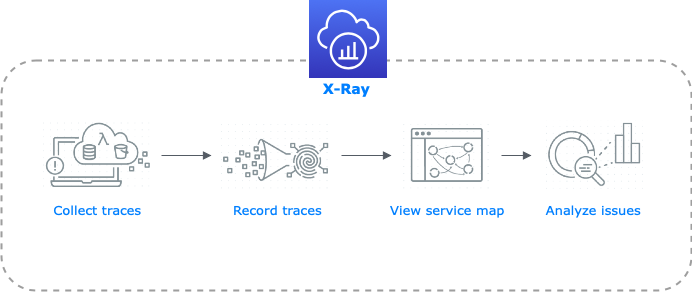
Informationen zu einer Webanfrage werden über die Anwendung hinweg von allen Services gesammelt.
Diese Daten werden zu einem sogenannten Trace kombiniert.
Aus diesen Traces wird eine Service Map erstellt, die die Verknüpfungen der Services darstellt. Zudem stellt uns diese Ansicht ein paar Informationen über die Services zur Verfügung (z.B. HTTP Status Codes, Latenz, andere Metadata, etc..)
Der Service, der ein unerwartetes Verhalten zeigt, kann nun anhand geeigneter Tools tiefer analysiert werden.
Eine Antwort
Hallo! Manchmal wünsche ich mir mehr solcher Artikel. Vielen Dank. Grüße